Week 04: Linked Lists and Hash Tables (Lab)
2026-01-29
Intro
Learning Objectives
By the end of this lab session, you should be able to:
- Develop an understanding of how stacks and queues work and implement basic algorithms using these data structures. ↪
- Manipulate linked lists through operations such as traversal and reversal. ↪
- Use hash tables to solve simple problems involving frequency counts (e.g., finding the majority element in an array). ↪
Overview of Lab Activities
Submit your work for the following activities to xSITe and/or Gradescope (as specified on each slide):
- Multiple-Choice Questions:
Submit using xSITe Quiz. Total 25 marks. - Implement a Queue Using 2 Stacks:
Submit using Gradescope. Total 25 marks. - Reverse a Singly-Linked List:
Submit using Gradescope. Total 25 marks. - Find the Majority Element in an Array Using a Hash Table:
Submit using Gradescope. Total 25 marks.
Multiple-Choice Questions
Exercise 1: Multiple-Choice Questions
On the xSITe course page, navigate to Assessments → Quizzes → Week 04 Lab Exercise 1: MCQs.
Select the best answer for each of the following five questions. You may refer to your notes or the lecture slides.
Exercise 1: Question 1
Consider a singly linked list with \(n\) nodes. You are given a pointer to the head of the list, but no tail pointer.
Which of the following operations can be performed in \(\Theta(1)\) time?
- Insert a new node at the end of the list
- Delete the last node of the list
- Insert a new node at the beginning of the list
- Search for a given key in the list
Exercise 1: Question 2
In a singly linked list, you are given a pointer to a node \(x\) that is not the last node in the list.
Which operation can be performed in \(\Theta(1)\) time?
- Delete node \(x\)
- Delete the predecessor of \(x\)
- Insert a node before \(x\)
- Find the last node in the list
Exercise 1: Question 3
A hash table uses chaining with \(m\) slots and stores \(n\) keys. Assume simple uniform hashing, and let the load factor be \(\alpha = n / m\).
What is the average-case time for an unsuccessful search?
- \(\Theta(1)\)
- \(\Theta(\alpha \log n)\)
- \(\Theta (1 + \alpha)\)
- \(\Theta (n)\)
Exercise 1: Question 4
A hash table uses chaining to resolve collisions. Each table slot stores a pointer to the head of a linked list.
Which of the following statements is always true for a hash table using chaining?
- The linked lists are kept in sorted order by key
- Each linked list contains at most \(\alpha\) keys
- The number of linked lists equals the number of stored keys
- Each key is stored in exactly one linked list
Exercise 1: Question 5
What property should a “good” hash function \(h(k)\) have when mapping keys to an \(m\)-slot hash table?
- Always produce prime numbers
- Distribute keys uniformly across slots
- Generate values larger than \(m\)
- Map similar keys to similar locations
Stacks and Queues
Stacks
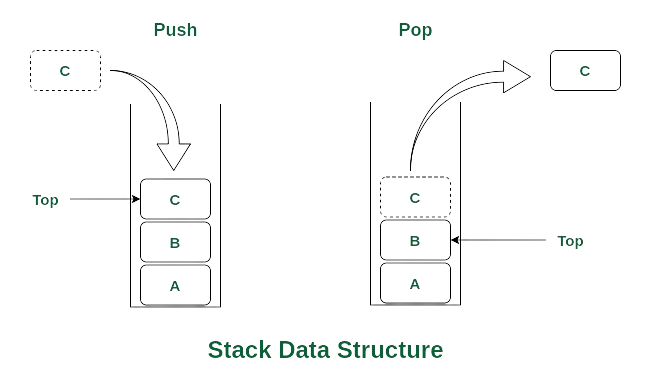
What is a Stack and How Does It Work?
A stack is a linear data structure that follows the Last In, First Out (LIFO) principle.
- The last element added to the stack will be the first one to be removed.
- Think of it like a stack of plates: you add new plates to the top and remove plates from the top.
Stack Basic Operations
- Push
- Add an element to the top of the stack.
- Pop
- Remove the top element from the stack.
- Top/Peek
- Retrieve the top element without removing it.
- isEmpty
- Check if the stack is empty.
C++ Implementation of Stacks
Stacks can be implemented using native C++ arrays or using libraries like <stack> in the Standard Template Library (STL):
Queues
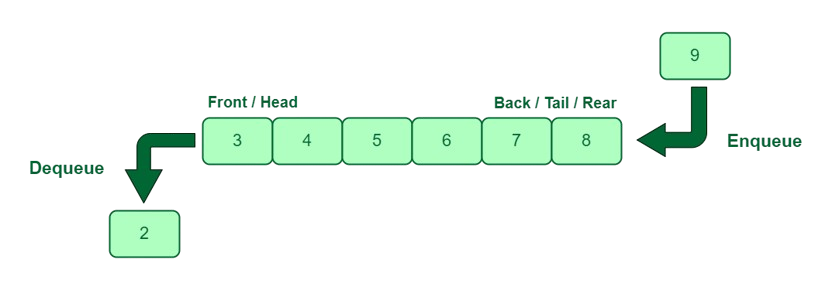
What is a Queue and How Does It Work?
A queue is a linear data structure that follows the First In, First Out (FIFO) principle.
- The first element added to the queue will be the first one to be removed.
- Think of it like a line of people waiting for a service: the first person in line is the first one to be served.
Queue Basic Operations
- Enqueue
- Add an element to the end of the queue.
- Dequeue
- Remove the front element from the queue.
- Front/Peek
- Retrieve the front element without removing it.
- isEmpty
- Check if the queue is empty.
C++ Implementation of Queues
Queues can be implemented using native C++ arrays or using libraries like <queue> in the Standard Template Library (STL):
Exercise 2: Implement a Queue Using 2 Stacks
Task
Your task is to implement a queue using 2 stacks, s1 and s2.
Template
You can find the template files on xSITe (.zip archive).
Complete the partial queue_using_2_stacks.cpp file. The make command will compile the project.
Submission
Implement the .enqueue() and .dequeue() methods of the Queue struct inside queue_using_2_stacks.cpp. Do NOT use std::queue in your implementation.
To receive credit for your work, upload your completed queue_using_2_stacks.cpp file to the Gradescope assignment titled Week 04 Lab Exercise 2: Implement a Queue Using 2 Stacks.
Exercise 3: Reverse a Linked List
Task
Given the head of a singly-linked list, your task is to implement a function that reverses this linked list iteratively.
Template
You can find the template files on xSITe (.zip archive).
Complete the partial reverse_linked_list.cpp file. The make command will compile the project.
Submission
Implement the reverseList() function inside reverse_linked_list.cpp.
Do NOT use any built-in functions for reversing the list (e.g., std::reverse).
To receive credit for your work, upload your completed reverse_linked_list.cpp file to the Gradescope assignment Week 04 Lab Exercise 3: Reverse a Linked List.
Hash Tables
C++ Implementation of Hash Tables (Unordered Map)
One of the ways to create a hash table in C++ is to use std::unordered_map. Sample code is presented on this and the following slide.
Here is an example of declaring, inserting, and accessing elements:
#include <iostream>
#include <unordered_map>
int main() {
// Declare unordered_map
std::unordered_map<std::string, int> umap;
// Insert elements into unordered_map
umap["apple"] = 1;
umap["banana"] = 2;
umap["cherry"] = 3;
// Access elements
std::cout << "apple: " << umap["apple"] << '\n';
std::cout << "banana: " << umap["banana"] << '\n';C++ Implementation of Hash Tables (Continued)
Additional operations include checking for existence, removing elements, and iterating:
Exercise 4: Find the Majority Element in an Array
Task
Given an array of positive integers, your task is to implement a function that finds the majority element in this array using a hash table. An element is considered a majority element if it appears strictly more than n / 2 times in an array containing n elements.
If no majority element exists, then the function should return -1.
Examples
[1, 2, 2]— element 2 is the majority element, since it appears \(2 > 3/2\) times in the array.[1, 2, 3]— no majority element exists, -1 is returned.[5, 5, 5, 8, 8, 8]— no majority element exists, -1 is returned. Both 5 and 8 appear 3 times, but either of them should appear at least \(6/2 + 1 = 4\) times to be considered the majority element.
Exercise 4: Find the Majority Element in an Array
Template
You can find the template files on xSITe (.zip archive).
Complete the partial majority_element.cpp file. The make command will compile the project.
Submission
Implement the findMajority() function inside majority_element.cpp.
Do NOT use any built-in functions for finding the majority element (e.g., std::count). You may however use std::unordered_map to instantiate your hash table.
To receive credit for your work, upload your completed majority_element.cpp file to the Gradescope assignment titled Week 04 Lab Exercise 4: Find the Majority Element.
Conclusion
Summary of Key Learning Outcomes
- Reviewed key properties of hash tables with chaining, including average-case search time under simple uniform hashing. ↪
- Understood how stacks and queues work, and implemented a queue using two stacks:
- Manipulated singly-linked lists by implementing an iterative reversal algorithm using three pointers. ↪
- Used
std::unordered_mapto build a hash table and solve a frequency-counting problem (finding the majority element). ↪ - Applied hash table lookups and insertions to count element occurrences in a single pass through an array. ↪
Outlook
Next week’s topics:
This lab introduced fundamental data structures—stacks, queues, linked lists, and hash tables—that appear throughout computer science. Next week continues with another essential structure:
- Binary Search Trees (BSTs): A tree-based data structure that supports efficient search, insertion, and deletion in \(O(h)\) time, where \(h\) is the tree height.
- Tree traversals: In-order, pre-order, and post-order traversal algorithms.
Week 04: Linked Lists and Hash Tables (Lab)